Scanned document digitization and data extraction
Discover an efficient and smart way to digitize and extract your document data. Here we extract bill of materials from engineering drawings
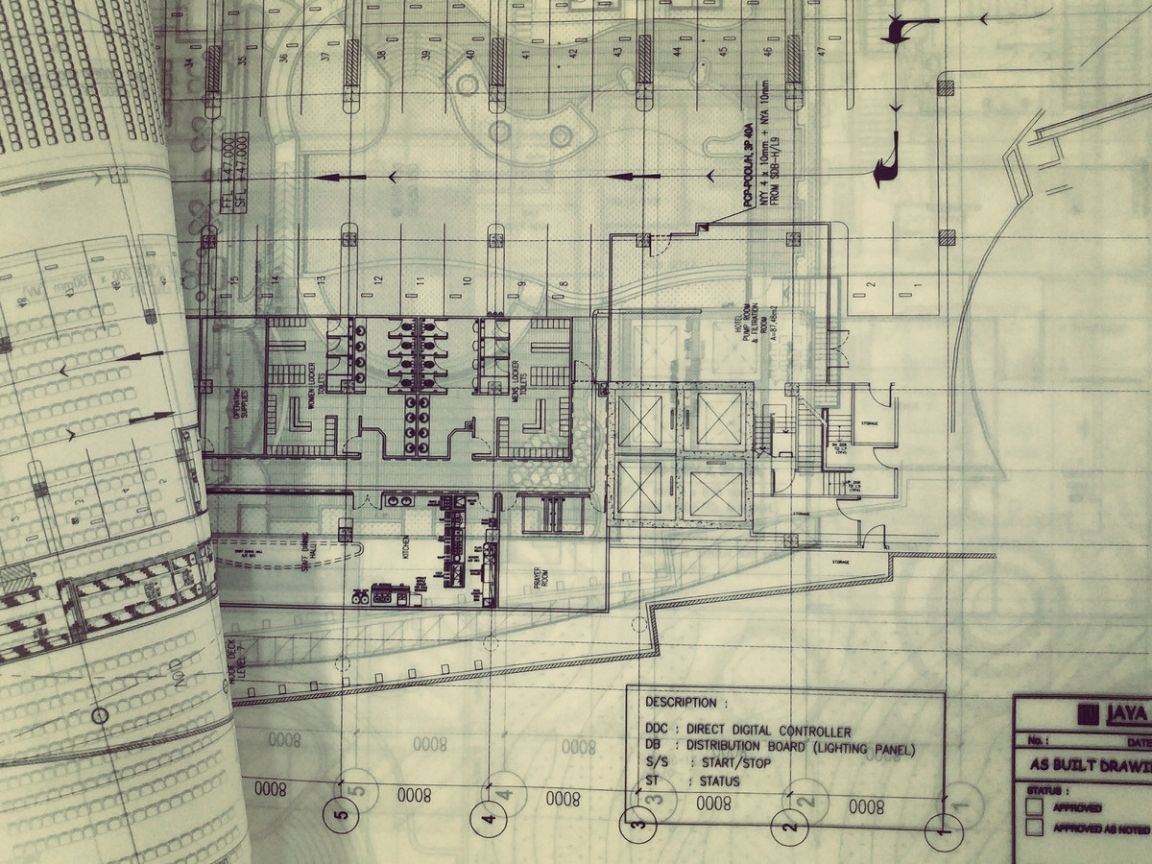
Problem statement
Engineering drawing is a type of technical document that represents the information about an engineering object in a graphical manner. It is commonly used by manufacturing companies as a means to communicate information relevant to the manufactured product or component. Extracting relevant information from the engineering drawings and converting them into searchable textual records is a laborious and time-consuming process. The client wanted to build an automation platform for their collection of engineering drawings. The tile block is a key piece of information on the drawing that can be used as a searchable index of records. To extract the information about the title table, we converted the textual data in the tables into searchable information by identifying the table border, the text inside the tables, and the relevant data.
Our solution
This project involves the integration of various advanced Machine Learning algorithms namely custom object detection, OCR conversion, text clustering with NLP, and named entity recognition. We will discuss the custom object detection module of the solution in this article. Since the title table is the primary object to be detected, we modeled this as an object recognition task using a novel Neural Network architecture. The data acquisition phase involved collecting the engineering drawings and annotating the segments pertaining to the title table. The object of interest also has some common features like table title row and columns depicting commonly used textual context. We also formulated a Machine Learning model to classify if a particular region is the title a table or not, using these features. We studied the performance for common classifiers like k-NN, SVM, SGD, etc, and narrowed it down to using an SVM classifier. We then packaged this solution as an Azure cloud function and exposed it as an HTTP API. Any new document arriving at the cloud function endpoint will then pass through the various ML detection and translation stages to produce a final CSV file pertaining to the textual data on the engineering drawing.
Key metrics
We are able to fully automate the process of engineering drawing document indexing with our multi-stage ML pipeline. This project was developed in a time frame of 45 weeks. The multi-stage ML pipeline was more than 90% accurate in the document conversion process.
Technology stack




Trusted Worldwide By Innovation Driven Companies