A RAG approach for building domain-specific LLM applications for the enterprise
In this blog we aim to explore the RAG approach in greater depth and examine why it is well-suited for building custom LLM apps from an enterprise technology perspective.
Balasaravanan Venugopal

In today's highly competitive business environment, more and more companies are recognizing the importance of building custom applications on Large Language Models (LLM). The role of LLM in simplifying business operations cannot be overstated, as it can lead to increased productivity and efficiency. However, with several approaches available for building custom LLM applications, choosing the right one can be a challenge. One approach that stands out from the rest is the Retieval Augmented Generation(RAG) approach, which offers several benefits such as reduced development time and costs, increased flexibility, and scalability. In this article, we aim to explore the RAG approach in greater depth and examine why it is well-suited for building custom LLM apps from an enterprise technology perspective. By doing so, we hope to provide valuable insights to organizations looking to leverage LLM technology to streamline their business operations and stay ahead of the competition.
LLMs are designed to learn from large amounts of textual data, which allows them to improve their accuracy significantly over time. They use sophisticated algorithms and statistical models that enable them to process complex information and extract key insights from vast amounts of data.
The core system of LLMs is built around the concept of next-text predictions, whereby the system is trained on massive amounts of tokens and is then tested to predict the most likely sequence of words based on previous input. This process results in a more sophisticated language model that can predict a user's next word or phrase with incredible accuracy. By leveraging this technology, businesses can provide their users with personalized, contextually relevant recommendations and responses that enhance the overall user experience. Furthermore, the use of LLMs in natural language processing can lead to more efficient communication and improved productivity across various industries.
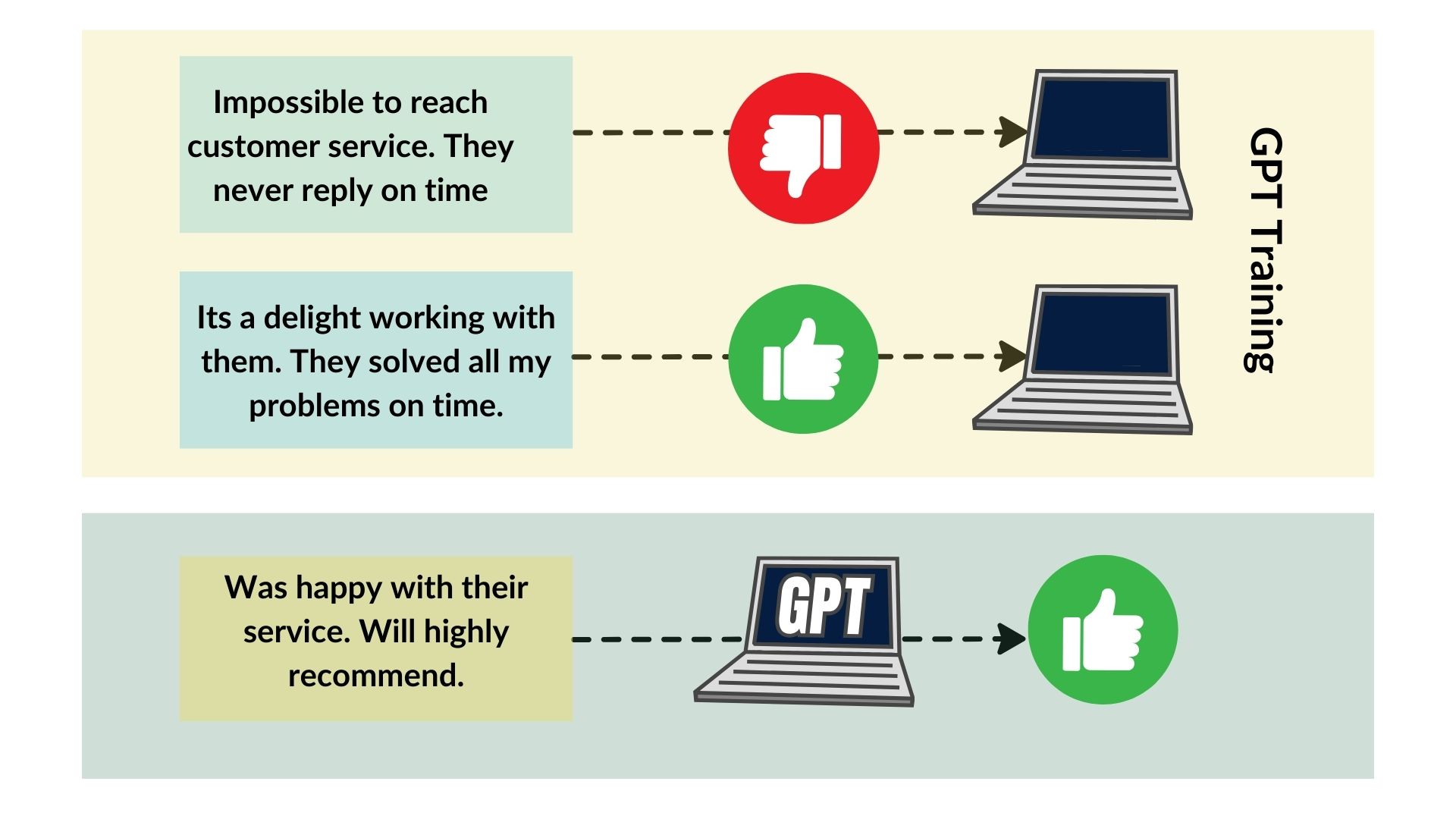
Limitations of LLM in the enterprise context
While Large Language Models (LLMs) have revolutionized natural language processing, there are several limitations to their application in enterprise use cases. One of the significant limitations is that these models rely on the data they have been trained on, which may be outdated or not applicable to specific industry domains. This can result in errors and misinterpretations that can have a negative impact on business operations. Moreover, these models may not have sufficient domain-specific knowledge, which can limit their ability to perform complex tasks such as extracting key insights from financial reports or medical records.
Another significant limitation of LLMs from an enterprise point of view is that they do not possess any internal knowledge about the enterprise. This can be problematic as it requires that companies provide these models with data that accurately reflects their operations and workflows. However, this is often not feasible as enterprises generate large volumes of data, and collecting and processing this data can be a daunting task. Additionally, the sensitive nature of enterprise data means that companies must ensure that data is protected and is only accessible to authorized personnel, which can further limit the usefulness of LLMs in enterprise use cases. Despite these limitations, LLMs remain a valuable tool in enterprise language processing and continue to evolve as technology advances.
Infusing domain knowledge into LLM
To overcome the limitations of Large Language Models (LLMs) from an enterprise use case point of view, there are several approaches that companies can adopt. One such approach is prompt engineering, which involves embedding the data context into the prompt. This approach allows the LLM to understand the context of the data, resulting in more accurate and relevant insights. By providing the model with context-specific prompts, it can provide better responses and predictions that are tailored to the enterprise's unique requirements.
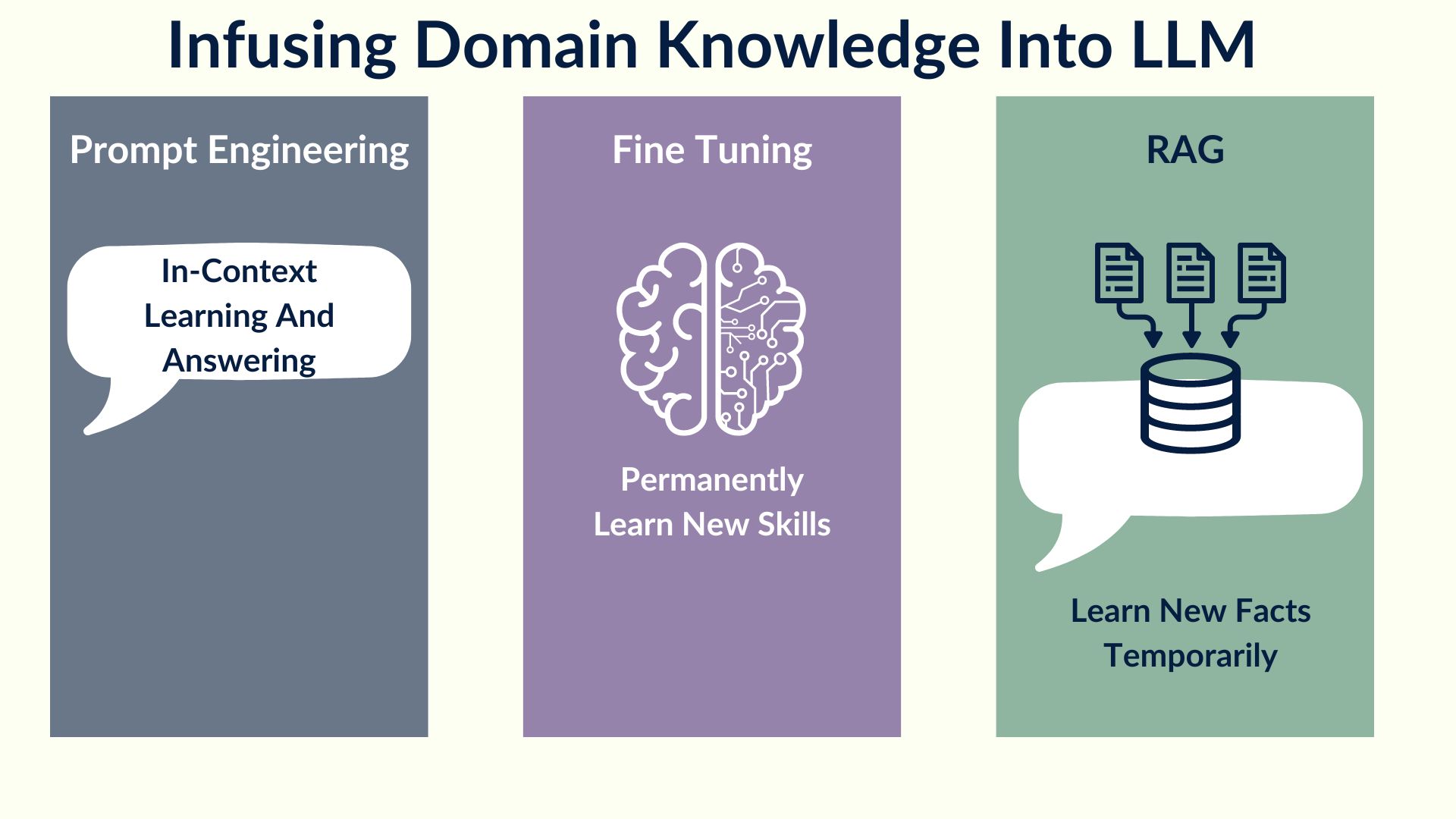
Another approach that companies can use to improve the effectiveness of LLMs is fine-tuning. Fine-tuning involves training the model on new data, which enables it to learn new skills permanently. This approach can be particularly useful for enterprises that operate in industries where data is constantly evolving, such as finance or healthcare. By fine-tuning LLMs, these enterprises can ensure that their models are up-to-date and can provide valuable insights that can inform decision-making.
Lastly, another approach that can be used to enhance LLMs' effectiveness is the Retrieval Augmented Generator (RAG). RAG allows the model to learn new facts temporarily and can be applied to a specific set of tasks. This approach can be particularly useful for enterprises that require specialized insights, such as analyzing legal or scientific documents. By allowing the model to learn new facts temporarily, RAG can help companies streamline their workflows and improve their overall productivity.
Overall, while LLMs have limitations, the application of these approaches can help companies overcome these limitations, making them a valuable tool in enterprise use cases. By embedding context-specific data into the prompt, fine-tuning the model on new data, or using RAG to learn new facts temporarily, companies can leverage LLMs to gain valuable insights and drive business growth.
A deep dive into RAG
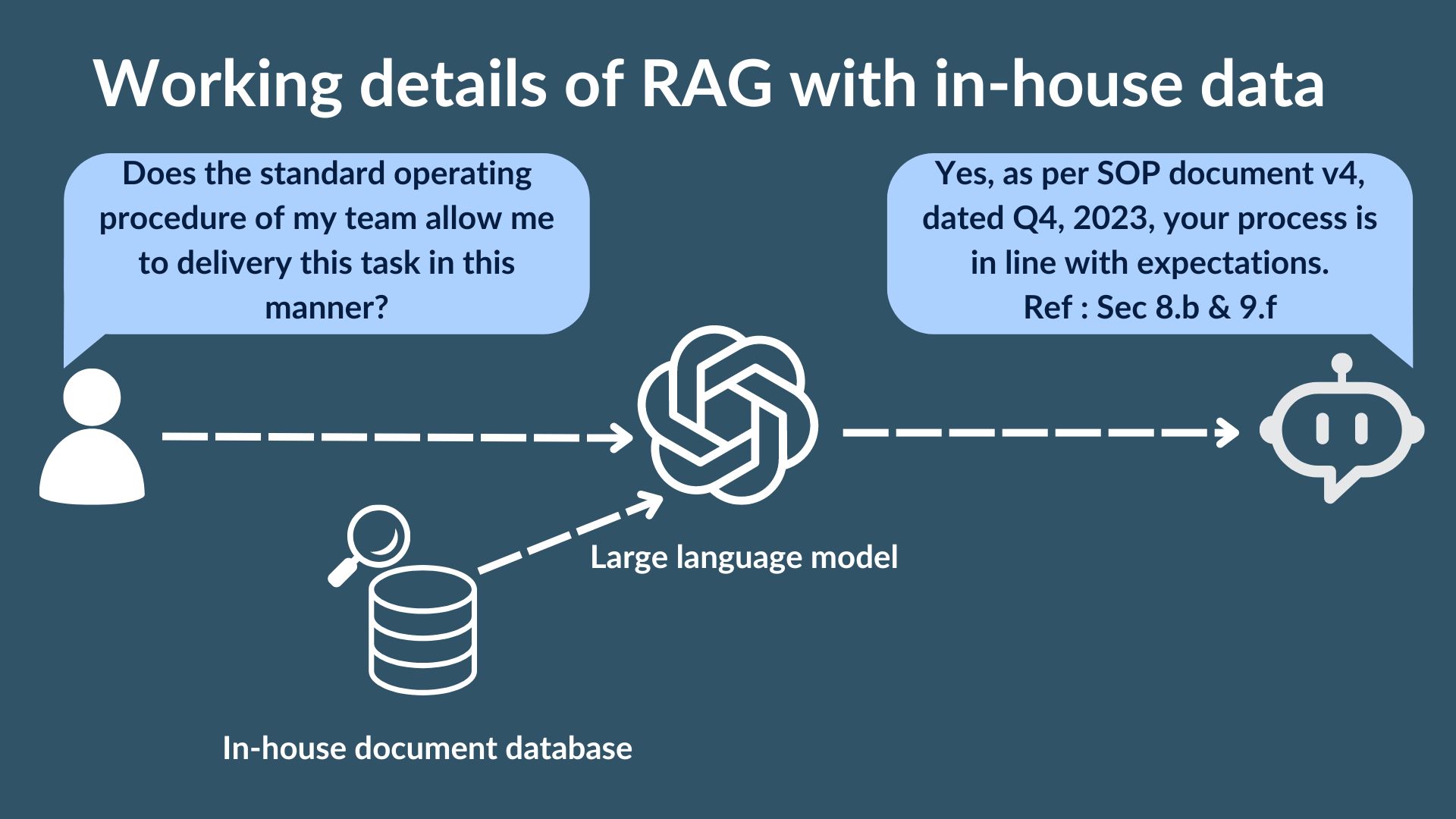
RAG is a powerful tool for building custom LLM applications. One of the key features of RAG is the ability to convert domain knowledge into a vectorized format, which allows for machine learning-powered text matching and ranking. This process involves collecting multiple documents from different sources and converting them into a numeric format that is easily understandable by machine learning algorithms. The resulting vectorized documents are stored in a single document store with corresponding indices, allowing for easy access and retrieval.
In addition to the vectorized documents, the RAG system comprises a vector searcher and indexer. These components enable the system to efficiently search and index vast amounts of data, facilitating faster and more accurate retrieval of information. This capability is particularly useful for industries with large amounts of data, such as finance, healthcare, and legal. By indexing and storing vectorized data, the RAG system can provide organizations with a unified view of their data, which can be leveraged to make more informed decisions and drive business growth.
When user input is given to the RAG system, it performs a comparison between the input and the vectorized documents to generate a suitable reply. This process involves matching the input with the most relevant vectorized document based on the context and content of the input. The RAG system then uses machine learning algorithms to generate an accurate and context-specific reply to the user's input. This capability enables organizations to provide personalized and context-specific responses to their users, enhancing the overall user experience and improving customer satisfaction.
Overall, the RAG system represents a significant advancement in LLM applications, providing organizations with a powerful tool for managing and analyzing large amounts of data. By converting domain knowledge into vectorized format and leveraging machine learning algorithms, the RAG system enables businesses to make more informed decisions. With its ability to efficiently search and index data and generate accurate and context-specific responses, the RAG system has the potential to transform the way businesses operate and automate.
Benefits of using RAG
Moreover, the RAG system provides citations and a thought process to the user, enabling them to understand the reasoning behind the response generated by the system. The citations are chunks of documents that match the user query, enabling the user to access the source of the information. This feature is particularly useful for organizations in industries with high regulatory requirements, such as healthcare or finance, as it provides transparency and accountability. By providing users with citations and a thought process, the RAG system facilitates better decision-making and enhances the overall user experience. With its ability to reason out the response generated by the machine learning algorithm and provide citations and a thought process to the user, the RAG system facilitates transparency and accountability, enhancing the overall user experience.
Components of a RAG
The RAG system comprises three main components that work together to provide accurate and context-specific responses to user queries.
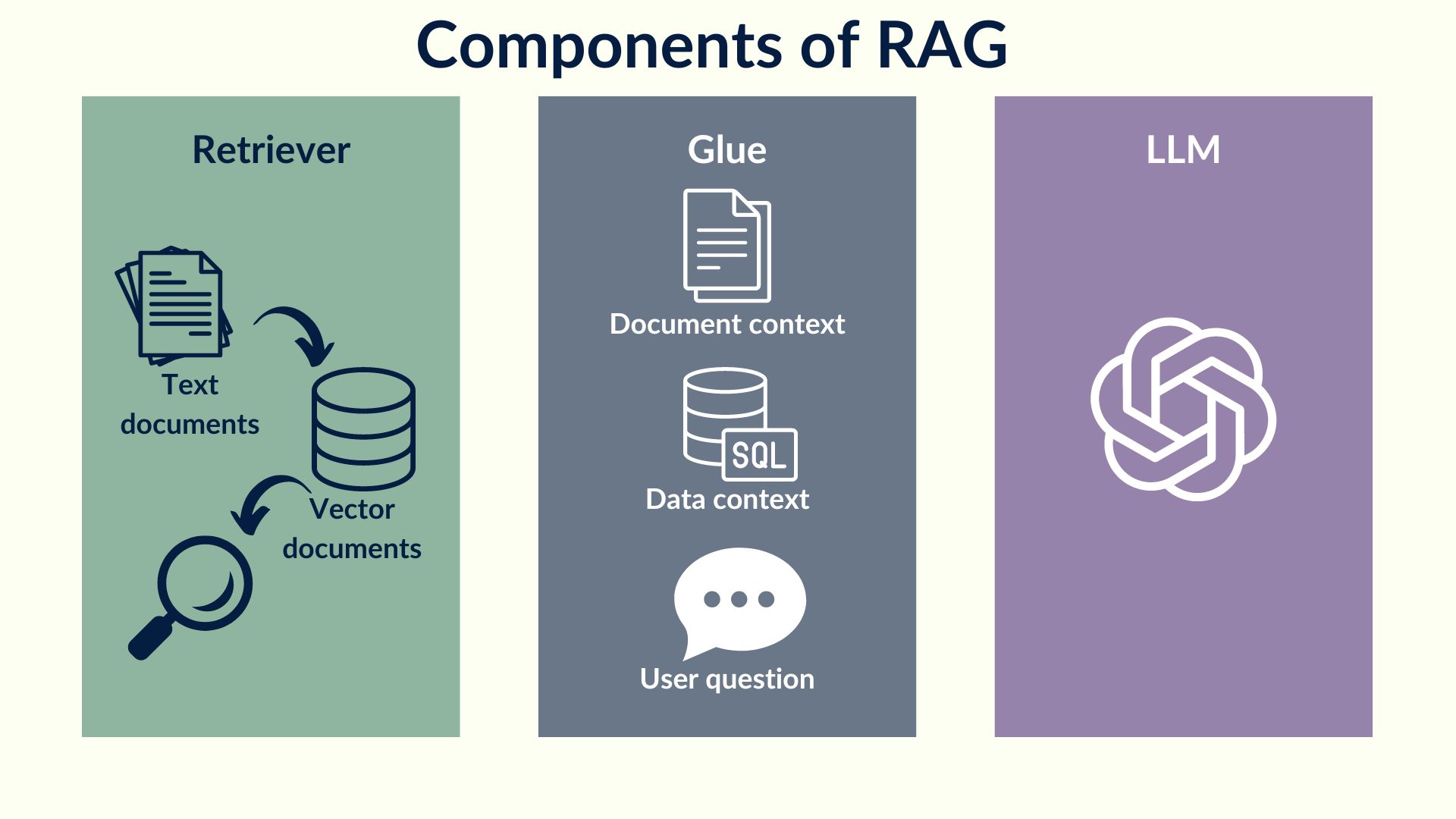
The first component is Retriever, which is a knowledge base that can match user queries with the data it holds. Retriever is powered by various search engines like Azure AI Search, Cosmos DB, and Elastic Search, among others. Retriever is responsible for collecting and indexing vast amounts of data, making it easy for users to retrieve information that is relevant to their queries.
The second component of the RAG system is the Large Language Model (LLM), which is responsible for answering user queries based on the results from the Retriever and adding citations along the way. LLM is powered by various language models such as GPT, Llama, Claude, and PaLM. The citations added by the LLM component provide users with access to the source of the information, enhancing transparency and accountability.
The third component of the RAG system is the Glue, which is a way to chain the Retriever to the LLM. Glue is responsible for integrating the Retriever and LLM components, enabling users to access accurate and context-specific information quickly and efficiently. Glue is powered by various tools like LangChain, LlamaIndex, and Semantic Kernel, which facilitate the seamless integration of the Retriever and LLM components. The Glue component ensures that the RAG system operates smoothly, providing users with a seamless and efficient experience.
Overall, the RAG system comprises three powerful components that work together to provide users with accurate and context-specific responses to their queries.
Trusted Worldwide By Innovation Driven Companies