Contrasting RAG approach with prompt engineering and fine-tuning in building domain-specific LLM applications for the enterprise
In this article, we will compare two methods — prompt engineering and fine-tuning — used in customizing Large Language Models (LLMs). Our analysis will encompass a thorough investigation into the benefits and shortcomings associated with each method.
Balasaravanan Venugopal

The skill vs knowledge debate is a longstanding discussion in education and psychology regarding the relative importance of acquiring skills versus acquiring knowledge.
Skill proponents argue that skills, such as critical thinking, problem-solving, and creativity, are more important than memorization of facts or information. They believe that skills are transferable across different contexts and are crucial for success in the rapidly changing modern world.
Knowledge proponents, on the other hand, argue that a solid foundation of knowledge is necessary to develop skills effectively. They believe that knowledge provides the context and framework within which skills can be applied and that a lack of foundational knowledge can limit a person's ability to think critically and creatively.
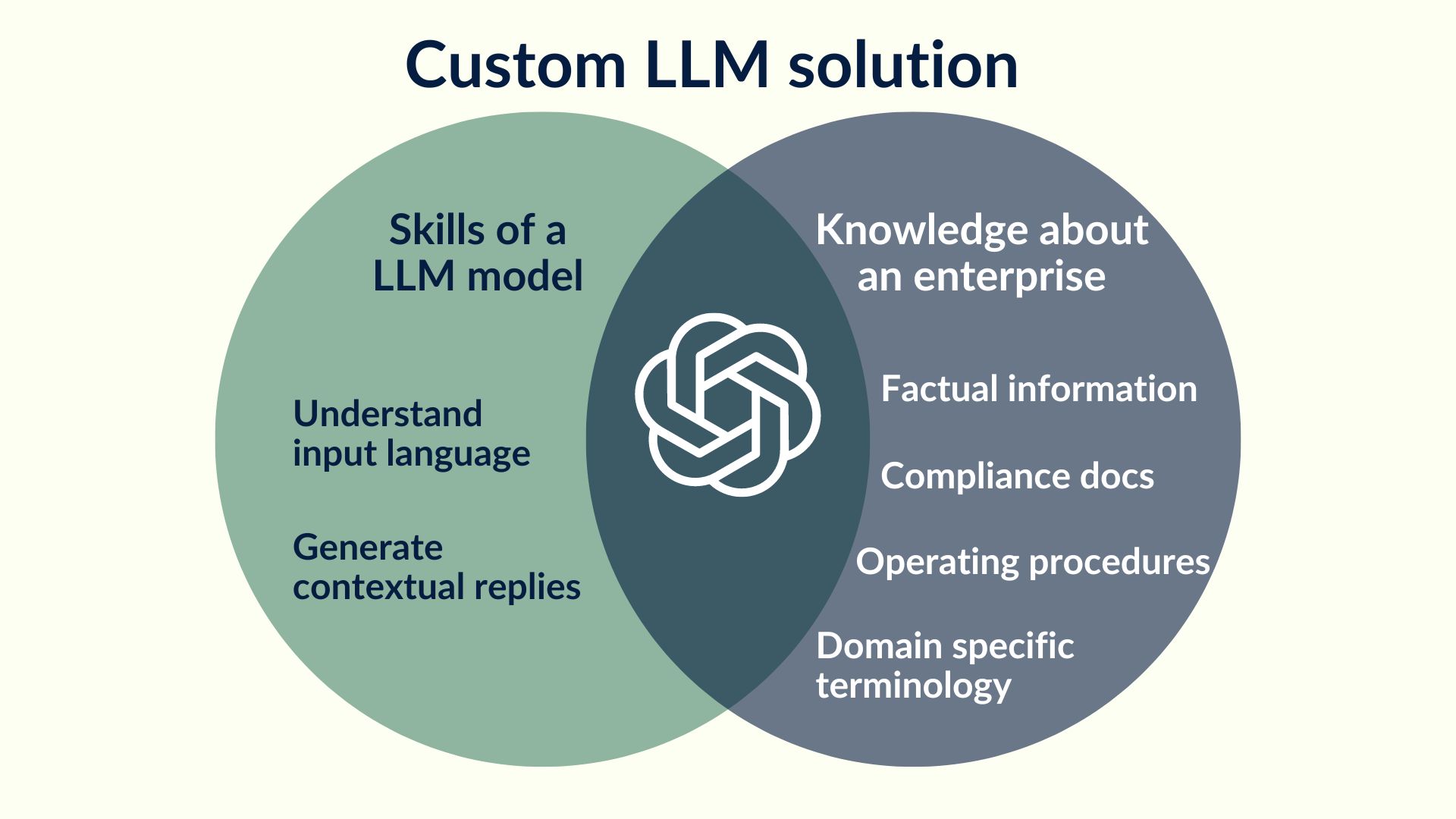
In the context of developing a customized Large Language Model (LLM) solution, adopting a combined approach of skill and knowledge acquisition is paramount for achieving optimal outcomes. The skill component of the solution is derived from the LLM and it lies in its ability to comprehend language and generate contextually relevant responses. Additionally, the knowledge element is derived from the domain-specific information unique to the enterprise. By integrating both skill and knowledge, the customized LLM solution is poised to provide significant value in addressing queries specific to the domain.
There are various ways in which a custom LLM can be built and RAG is one the more popular methods to infuse domain knowledge into custom LLM. This was discussed earlier in the article “Link to Article 1”. In this article, we will compare other two methods—prompt engineering, fine-tuning —used in customizing Large Language Models (LLMs). Our analysis will encompass a thorough investigation into the benefits and shortcomings associated with each method. Furthermore, we aim to quantify these benefits through the lens of enterprise use cases. By delving into these methods, we seek to provide valuable insights into how organizations can leverage LLM customization to enhance their operational efficiency and decision-making processes.
What is prompt engineering?
Prompt engineering is the systematic process of defining the context, constraints, style, and formatting for a large language model (LLM) to ensure it responds accurately and appropriately to user queries. Context involves providing overall direction and background for the query. Constraints (or guards) serve as mechanisms to limit the LLM’s responses when the context is unclear or out of scope. Style refers to guiding the LLM to produce responses in a specific tone and with a desired level of detail. Formatting specifies the structure of the output, such as whether the response should be in the form of bullet points, a list, or a set of paragraphs.
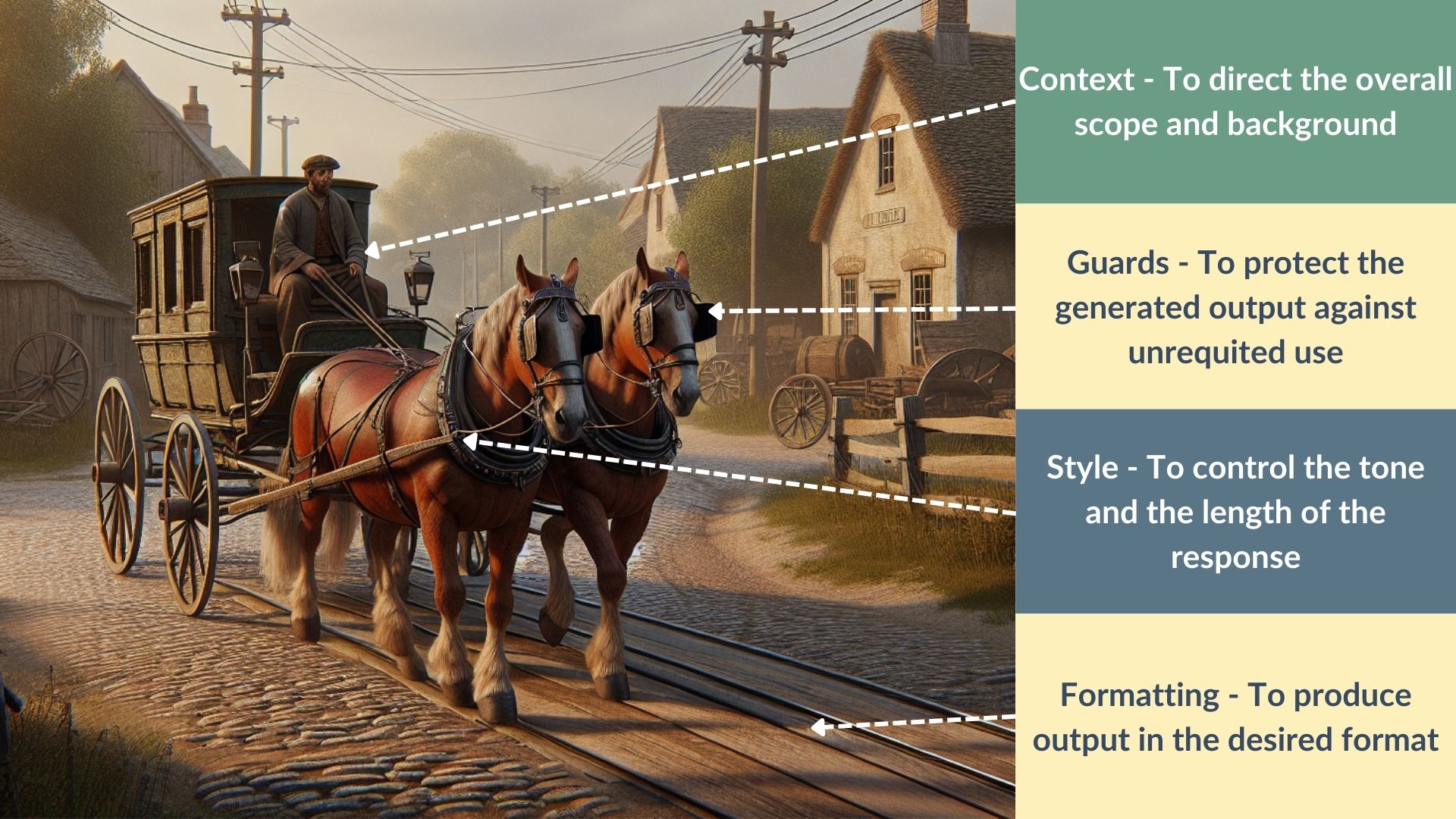
Prompt engineering is akin to the art of guiding a horse-drawn coach. To ensure that the horse travels in a straight and purposeful path, its eyes are fitted with blinders, preventing distractions and keeping its focus on the road ahead. In this analogy, the coachman represents the prompt engineer, who provides the necessary context and direction for the journey, ensuring the horse reaches its intended destination.
The coachman, much like a prompt engineer, plays a crucial role in defining the journey's parameters. By setting the context, the coachman ensures that the horse understands the overall direction and purpose of the trip. This mirrors how a prompt engineer provides the LLM with specific background information and guidelines, enabling it to generate relevant and accurate responses tailored to the user's query.
The blinders on the horse symbolize the constraints or guards placed on the LLM, limiting its scope and preventing it from veering into irrelevant or off-topic areas. This ensures that the responses remain focused and within the defined context, much like how blinders keep the horse attentive to the path laid out by the coachman.
Furthermore, the saddle and the road represent the style, speed, and gait of the horse in its journey. In prompt engineering, these elements are analogous to the instructions given to the LLM regarding the tone, detail, and formatting of its responses. Just as the saddle and road conditions influence how the horse moves, the prompt engineer's specifications govern how the LLM structures and presents its output.
In summary, prompt engineering is a sophisticated practice that involves providing clear context, setting constraints, and defining style and formatting to guide the LLM's responses. Doing so ensures that the interaction between the user and the LLM is productive, accurate, and aligned with the intended objectives, much like a well-guided coachman leading a horse to its destination.
When should an enterprise choose prompt engineering?
One of the key factors in prompt engineering involves accessing and integrating the context and background of the query. In an enterprise setting, this context is typically domain-specific. It encompasses factual details about the enterprise, its operating procedures, compliance policies, and other domain-specific details. This domain knowledge is not inherently visible to large language models (LLMs), making it necessary to infuse this specialized knowledge into custom LLM applications. By embedding this domain-specific information into the prompt, the LLM can generate more accurate and relevant responses tailored to the enterprise's unique needs.
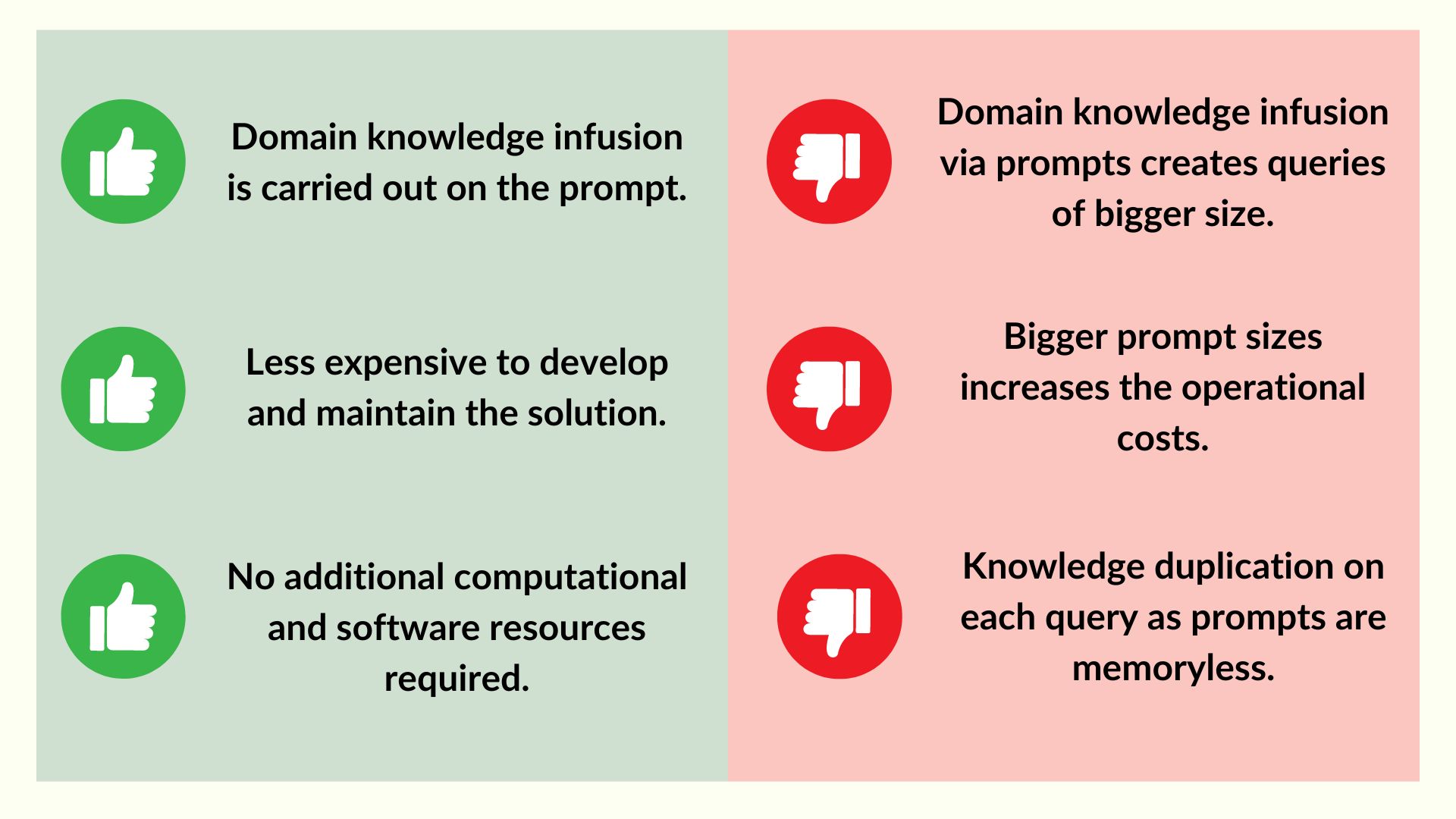
On the other hand, building LLM applications through prompt engineering offers a streamlined approach, treating the LLM as a black box. This method facilitates rapid development since the application is essentially ready once the prompts are formulated. Consequently, the initial setup is straightforward, requiring minimal additional infrastructure or development time. When domain information is updated, the prompts can remain unchanged, though the queries must be reissued to allow the LLM to process the new data and generate the necessary results. This dynamic interaction ensures that the LLM continually produces relevant outputs based on the most current domain knowledge.
However, in domains characterized by perpetual and systematic updates to domain knowledge, the costs associated with this approach can become prohibitive. Frequent updates necessitate repeated prompt executions, each incurring costs due to the token consumption. Over time, these recurring expenses can escalate, potentially outweighing the benefits of the initial simplicity and ease of setup. Therefore, while prompt engineering offers a quick and efficient pathway to developing custom LLM applications, careful consideration of the long-term costs and scalability is essential, particularly in rapidly evolving domains.
Balancing the immediate advantages of prompt engineering with the potential long-term financial implications requires strategic planning. Enterprises must assess their specific needs, the frequency of domain knowledge updates, and the associated costs to determine the most sustainable approach to leveraging LLM technology. By doing so, they can optimize the performance and cost-efficiency of their custom LLM applications, ensuring they derive maximum value from their investment.
When is it better to use fine-tuning to customise a LLM model?
LLM fine-tuning is a process that involves training a large language model using in-house data specific to an enterprise. This data can encompass a wide range of information, including factual data, compliance documents, domain-specific terminology, and operating procedure documents. By leveraging this in-house data, the LLM can be tailored to better understand and generate responses that are highly relevant to the specific needs and requirements of the enterprise.
Given sufficient data and adequate training iterations, the LLM gradually internalizes this domain-specific information, resulting in a fine-tuned model. This fine-tuned model is adept at understanding and responding to queries within the enterprise's specific context, providing more accurate and contextually appropriate outputs compared to a generic, pre-trained model.
The resulting domain-specific fine-tuned model represents a significant enhancement over standard models. It is tailored to the unique operational and informational landscape of the enterprise, allowing it to handle specialized queries with a high degree of precision. This customization not only improves the quality and relevance of the generated responses but also enhances the overall utility of the LLM within the enterprise setting.

To illustrate this point, let us consider the example of agricultural tractors. At one end of the spectrum, we have the standard, run-of-the-mill general-purpose tractors that are designed to perform a wide range of tasks. On the other end, we have highly specialized tractors that are tailored to perform specific functions such as de-weeding and harvesting. The process of fine-tuning can be envisioned as the transformation of a standard tractor into a specialized machine that is optimized for a particular use. This involves making precise adjustments and modifications to the tractor's components and systems to enhance its performance and efficiency for a specific task. By fine-tuning a tractor, farmers can achieve greater precision and productivity in their operations, ultimately leading to improved yields and profitability.
Likewise, fine-tuning an LLM with in-house data transforms it into a powerful tool for addressing the specific challenges and requirements of the enterprise. By embedding the model with detailed domain knowledge, enterprises can achieve greater efficiency and effectiveness in their AI-driven applications, ensuring that the LLM serves as a valuable asset in their operational toolkit.
One key advantage of this approach is the use of large samples of domain-specific data, resulting in an incredibly accurate and contextually correct model. By leveraging this data, we're able to ensure that the model produces highly relevant responses that align with the desired context.
Another key benefit of the fine-tuning approach is its cost-effectiveness. Since we can use simpler prompts without the need to impart domain knowledge, this reduces the cost of maintaining the model. Additionally, the use of domain-specific data allows us to create more targeted prompts, further streamlining the training process.
However, it's important to note that the training process can be quite elaborate. Creating a custom model requires a fine-tuned understanding of training and hyperparameter tuning, which can be time-consuming. Additionally, if the dataset used for training is not comprehensive, the model may be prone to underfitting or overfitting, leading to inaccurate responses.
Finally, it's important to recognize that a custom model requires specialized cloud computing resources to execute effectively. While this may require a larger investment upfront, it ultimately leads to more accurate and reliable responses, ensuring that the model aligns with your specific business needs and goals.
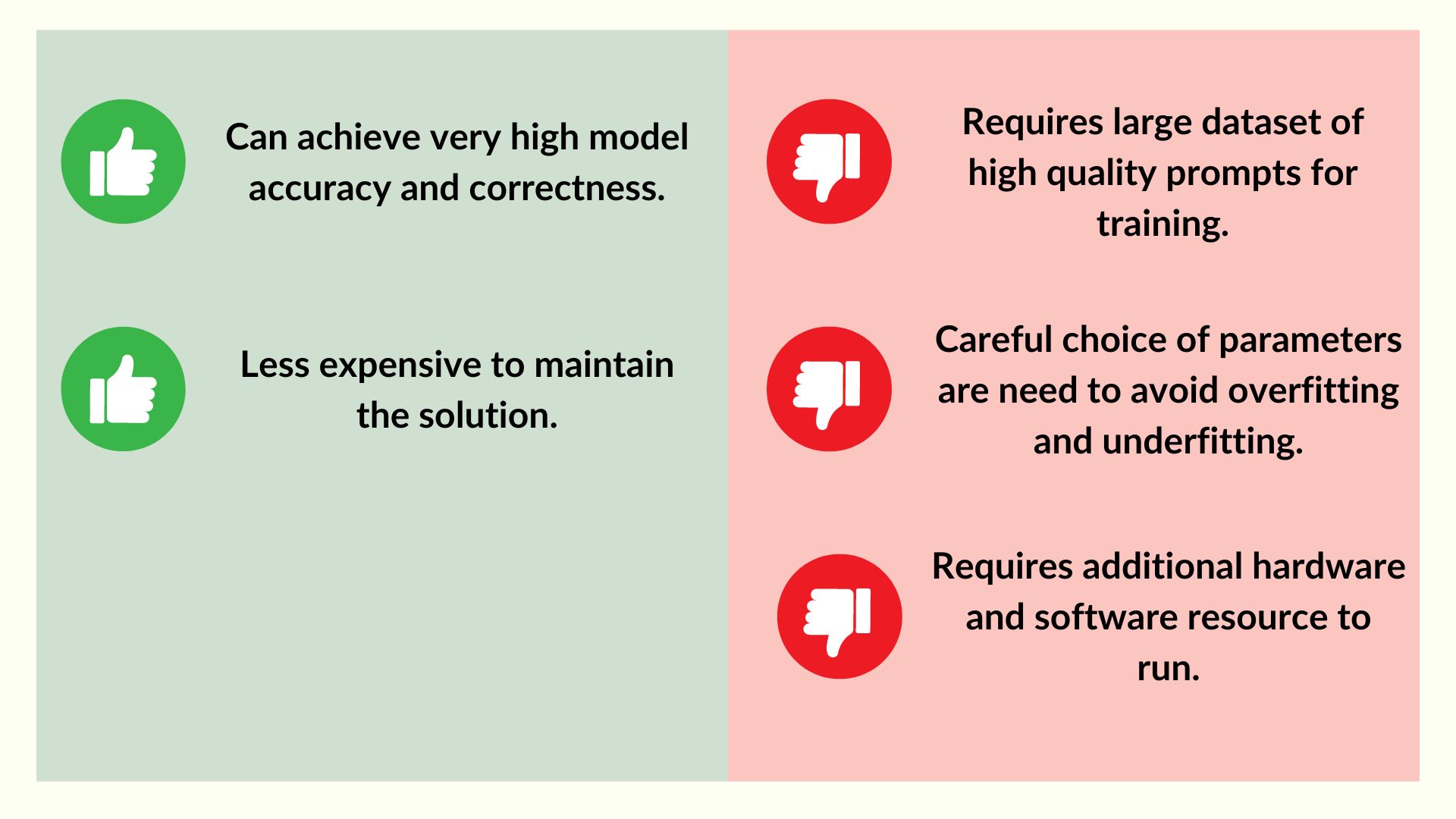
In conclusion, the fine-tuning approach to customizing the LLM model provides a highly accurate and cost-effective solution for businesses looking to create a custom language model. While the training process can be elaborate, leveraging large samples of domain-specific data ensures that the model produces contextually relevant responses. Additionally, specialized cloud computing resources allow for more reliable execution, ensuring that the model aligns with your business needs and goals.
Choose fine-tuning if one or more of the following is true. You have a large dataset of very high quality for training. You have access to LLM training infrastructure. You require a very accurate model. You are not worried about the costs and timeframe involved in LLM training. You are not worried about the costs in running a custom model.
Choose prompt engineering if one or more of the following is true. You do not have training dataset and LLM training infrastructure. You require a LLM application that is quick to develop and use. You are not worried are the running costs of the LLM application. You can work with a model that is accurate to a fair extent.
Choose RAG if one or more of the following is true. You want the application to be fully functional irrespective of the size of the enterprise dataset. You want to optimize running costs of the LLM application. You can work with a model that is accurate to a fair extent. You want to be able to reconfigure the enterprise dataset . You want to be develop the application fairly quickly.
Key Metrics
We are a team that values efficiency, innovation, and the pursuit of excellence in everything we do. We are a high performance team that is passionate about bringing AI and Cloud computing technologies to a larger industry audience. We have accomplished so much in such a short amount of time!
8
Years in business
40+
Happy clients
120+
Completed projects
2 %
Hire top talent
100 %
Certified team
90 %